How to calculate the mathematical strength of a random selected password.
Since a username together with a password are still the most common way to authenticate against computer systems it is both important and interesting to understand the different factors that determine the actual strength of the parts that is combined to create a “password”.
Knowing this could help us for example to define password policies that make actual sense, and allow us through a conscious choice create personal passwords that are of a reasonable strength for its intended purpose and threat level.
Often both end users and administrators are forced to define their passwords from some kind of vague perception of what makes a password “weak” or “strong”. If we actually understand the mechanics of passwords and password cracking we will instead be able to do informed choices.
There are many articles and discussions available on the Internet regarding password selection and password strength, however not always easily accessible for someone new to the subject. The goal for this series of articles is to provide a clear and easy-to-understand overview and analysis of these sometimes complex matters.
The basic strength
To begin, the basic theoretical mathematical strength of a password is determined by two factors:
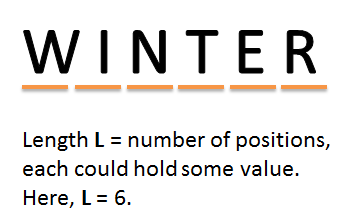
1. The length of the password string, in this article called L, i.e. the total number of used positions in a specific password. Often the minimum length is determined by a policy enforced to the end user.

2. The potential “complexity” of each position of the password. The “complexity” is the number of different values that could be inserted into each position.
For example, if we assume that a password could only include numbers (0-9), much like a typical PIN code, the “complexity” would be 10, as there are ten different values possible for every single position in the code/password.
If a password for some reasons could only include uppercase characters from the English alphabet then the complexity would be 26, from the characters A-Z. Given both upper and lowercase characters the “complexity” would raise to 52 (a-z, A-Z).
With numbers (0-9) possible as well as characters the potential complexity for each position will be 62. (This combination with a-z, A-Z and 0-9 is often called “alphanumerical”.)
In this article the possible “complexity” of each position is called C.
From the values of L and C we can calculate the mathematical strength of a random password.
(Note that many passwords selected by humans are often not “random”. The strength will in many cases be greatly reduced by poorly chosen predictable passwords for various reasons. See part five for a detailed discussion of how non-random password could be broken. In part eight of this article series different techniques for good password selections will be discussed.)
In this context and with the basic assumption that the password is indeed random, the strength could be determined by combining L (length) and C (complexity) in a simple formula.
Assume we only use upper case characters from the English alphabet (C=26) and the password is only two characters long (L=2). Since each of the two positions could hold 26 different possible values the total amount of combinations is 26 x 26 = 676, e.g. AA, AB, AC, AD … ZZ.
This could also be expressed as C^L, i.e. here 26^2.

If the length was increased to three we would get 26 x 26 x 26 (i.e. 26^3) possible combinations = 17576.
An interesting fact is that the number of possible combinations rapidly increases as more length is introduced.

If someone – for some reason – would be aware that a unknown password is made up of only uppercase characters and that the length is just four, one would possible by intuition assume that it would be possible to “by hand” manually try the different combinations to logon. However as noticed from the rapid increase of the possible combinations the total number of possible four character passwords is actually quite high:
26 x 26 x 26 x 26 = 456 976
That is, to test all possible combinations of a four character upper-case only password someone would need to go through over four hundred thousand tries to be sure to find the correct phrase.
This means that just a four character random password would be enough to in reality rule out a human intruder from brute force by hand.
Because of the high number of possible combinations from just a really short password it is however very likely that an intruder would strive to utilize computer power to launch the password attempts. While four hundred thousand tests would be impossible in practice for a human it would be trivial for a computer, which follows that both password policies and the passwords themselves must be selected from that fact.
The basic strength, as in the maximum number of possible combinations, here called M, could be written as:
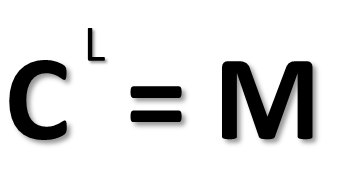
The complexity value C raised to the password length L = maximum combinations (M) needed to guaranteed find the correct passphrase.
To display how the maximum combinations (M) changes by adding complexity we could observe the difference by adding more “allowed” characters in the phrase. For example, assume that we could have both lower and uppercase characters (giving complexity C = 52) while still using a length of only four we would get:
Formula C^L: 52 ^ 4 = 7 311 616
That is, by adding more possible characters to each position the total maximum combinations increases dramatically. In this case the earlier four character password with only uppercase letters (A-Z) gave M to around 400 000 possible combinations, we see that using both upper and lower case (A-Z, a-z) increases the maximum combinations to over seven million.

By introducing numbers (0-9) as possible values together with a-z and A-Z the complexity will increase further. With C = 62 and a length of still four characters would give:
C ^L = M 62 ^4 = 14 776 336
If we also include the possibility to use some “special characters” as !”#¤%&/\()=+-:* we would get around 15 more possible combinations for each position, which would raise the complexity value C to 77.
(Note that there of course are many more “special characters” than these 15, but for the sake of the argument we will include those most commonly used in writing and most easily accessible on the keyboard for the typical user depending of localized keyboard setup.)
The complexity value is not what kind of characters a certain password necessarily does contain, but what it could contain.
With a four character password that COULD include upper and lowercase characters, numbers and 15 “special” characters the maximum combinations will be:
77^4 = 35 153 041
Thus, a very short four characters, but “complex”, password has actually over 35 million possible combinations.
To summarize and to visualize the differences, let us look at a short four character password with different complexity:

As noted the maximum value increases rapidly while keeping the same length, but adding complexity.
We will now investigate how the numbers will change by instead increasing length (L), while keeping the complexity very low, for example only uppercase characters, (C=26), we get:
26^4 Example password: RVHQ 456 976
26^5 Example password: RVHQT 11 881 376
26^6 Example password: RVHQTJ 308 915 776
One interesting observation is that adding just a little more length (L) rapidly increases the maximum possible combinations (M) as well.
As noted earlier, while a four characters “complex” password with C = 77 has around 35 million combinations, a “non-complex” password with just a small increase of the length to six character – but with only uppercase letters – has over 300 million possible values.
For example, if comparing a shorter but “complex” password of, e.g., X#8a vs a simpler, e.g., EUGCRQ the latter is actually around ten times stronger (still under the presumption that the phrase is made up of random selected characters).
If looking at a “complex” six character password with the earlier formula C^L=M we get:
77^6 = 208 422 380 089
That is, the six character password has over 200 billion possible combinations (still assuming a random selection).
However, if increasing a non-complex uppercase-only password to the length of eight gives almost the exact same strength (actually even 400 million more possible combinations):
26^8 = 208 827 064 576
That is, if comparing two example passwords:
C=77, L=6 X#8a*Q = 208 422 380 089
C=26, L=8 EUGCRQAO = 208 827 064 576
the latter one is in fact stronger, while still having a very low degree of complexity, but the two extra positions in length adds greatly to the maximum different combinations.
One of the most primary observations that could be made is that length, generally, is of greater importance than the complexity.
Would this mean that an eight character uppercase password would be a good choice? As shown, it would be in every practically way impossible for a human to systematically, but manually, test 200 billion logon attempts. However, as we will see in part three of this article, this will not be any real obstacle for a computer doing offline brute force attacks and we would need a much higher possible M values to defend against that threat.
To summarize, the mathematical strength of a password is the length of the string raised to the possible complexity of each position.
In the next part of the article we will discuss the so called entropy value of a password.
If you have any question or comment, please leave your comment below.
very nice explanation. how can i read the full article?
Hello Rickard,
The contents of this article are about as far as I’d gotten on my own. Where is the rest of your discussion? I’m trying to figure out precisely how fast the pool of potential passwords is reduced by requiring complexity, rather than allowing it.
I have tried totaling up the number of impermissible passwords (those that don’t comply with strict complexity rules) and subtracting that from the total pool. The formula isn’t nearly as neat and as S^L.
And following that, I’d like to see if requiring some, but not total complexity would be a better balance. For example, allowing [a-z, A-Z, 0-9, SpecialChars] but requiring two or three of those might make the passwords sufficiently resistant to a brute-force attack, but still memorable to human minds. Intuitively, it seems that those would allow a lot more potential passwords into the pool than requiring all four character types in every password choice, and that would be a wiser course than strict complexity.
Of course, “length is better than complexity” was my original thesis, so I’m pleased that we are in agreement on that.
If you’ve written further on this topic, I’d like to read that, too.
Stay safe & stay healthy.
*should be: [The formula isn’t nearly as “neat and tidy” as S^L.]