Network performance with VMware paravirtualized VMXNET3 compared to the emulated E1000E and E1000.
In the first article the general difference between the adapter types was explained.
In this article we will test the network throughput in the two most common Windows operating systems today: Windows 2008 R2 and Windows 2012 R2, and see the performance of the VMXNET3 vs the E1000 and the E1000E.

To generate large amounts of network traffic I used the iperf tool running on two virtual machines, one iperf “client” and the other as “server”. I have found that the following iperf settings generates the best combination for network throughput tests on Windows Server:
Server: iperf -s -w 64k -l 128k
Client: iperf -c <SERVER-IP> -P 16 -w 64k -l 128k -t 30
The test was done on HP Proliant Bl460c Gen8 with the virtual machines were running on the same physical host to be able to see the network performance regardless of the physical network connection between physical hosts/blades.
All settings on the E1000, E1000E and VMXNET3 was default. More on possible tweakings of the VMXNET3 card settings will be explained in a later article.
(It shall of course be noted that the following results are just observations from tests on one specific hardware and ESXi configuration, and is not in any way a “scientific” study.)
Test 1: Windows 2008 R2 with the default E1000 adapter
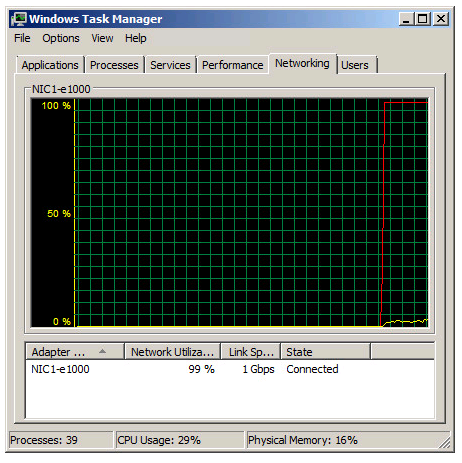
Two Windows 2008 R2 virtual machines, one as iperf server and the other as client, with the test running in 30 seconds.
As noted in the Task Manager view the 1 Gbit link speed was maxed out. A somewhat interesting fact is that even with the emulated E1000 adapter it is possible to use more than what “should” be possible on a 1 Gbit link.
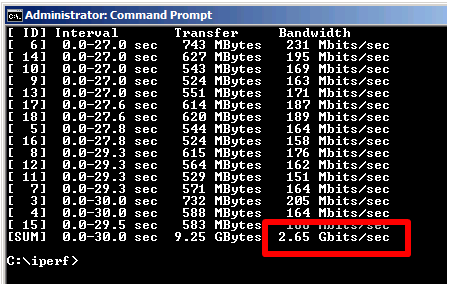
From the iperf client output we can see that we reach a total throughput of 2.65 Gbit per second with the default E1000 virtual adapter.
Test 2: Windows 2008 R2 with the VMXNET3 adapter

The Task Manager view reports utilization around 39% of the 10 Gbit link in the Iperf client VM.

The iperf output shows a total throughput for VMXNET3 of 4.47 Gbit / second over the time the test was conducted.
The VMXNET3 adapter demonstrates almost 70 % better network throughput than the E1000 card on Windows 2008 R2.
Test 3: Windows 2012 R2 with the E1000E adapter

The E1000E is a newer, and more “enhanced” version of the E1000. To the guest operating system it looks like the physical adapter Intel 82547 network interface card.
However, even if it is a newer adapter it did actually deliver lower throughput than the E1000 adapter.

Two virtual machines running Windows 2012 R2 with the iperf tool running as client and server.
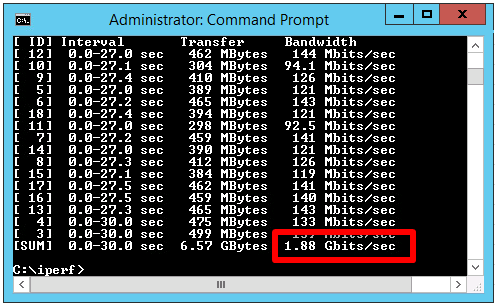
E1000E got 1.88 Gbit / sec, which is considerable lower than the 2.65 Gbit/s for the original E1000 on Windows 2008 R2.
Test 4: Windows 2012 R2 with the VMXNET3 adapter

The two Windows 2012 R2 virtual machines now running with VMXNET3 adapter got the following iperf results:
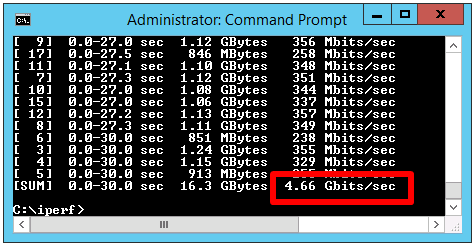
The throughput was 4.66 Gbit/sec, which is very close to the result of VMXNET3 on Windows 2008 R2, but almost 150 % better than the new E1000E.

In summary the VMXNET3 adapter delivers greatly more network throughput performance than both E1000 and E1000E. Also, in at least this test setup the newer E1000E performed actually lower than the older E1000.
The test was done on Windows Server virtual machines and the top throughput of around 4.6 Gbit/sec for the VMXNET3 adapter could be the result of limitations in the TCP implementations. Other operating systems with other TCP stacks might achieve even higher numbers. It shall be noted also that these test was just for the network throughput, but there are of course other factors as well, which might be further discussed in later articles.
Thank you for these numbers.
It would be great also to know, what influence this test with different network adaptors has had to the hosts CPU.
Thank you for your reply Urs.
I will publish the CPU usage numbers in the next article in the VMXNET3 series.
Regards, Rickard
Urs, correct because all of that has to do with TCP/IP OFFLOAD (CHIMNEY) to CPU. And if the NIC runs faster the CPU will have cycles to handle. That esp. comes into mind when you do CPU heavy things like DB, Exchange.
http://www.butsch.ch/post/IT-Slow-Exchange-2013-LAB-slow-Outlookexe-under-ESXi-55.aspx
Understanding TCP Segmentation Offload (TSO) and Large Receive Offload (LRO) in a VMware environment (2055140)
https://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2055140
Thank you! This was very useful.
Eagerly awaiting Part 3 of the network adapter comparison!
I remember that E1000E improvements were largely feature wise, including Jumbo Frames, for example. It would be interesting what might show up with larger frames.
Even if the cases of virtual machines using Jumbo Frames might be lower than, e.g. ESXi storage network use cases, it would definitely be interesting to investigate and compare. Thanks for your reply and idea.
Great article. Really it was useful.
Thanks for your great article.
I was able to resolve a major issue with my wrong choice of e1000e driver.
Thanks
Chris
Nice to hear that Chris, thanks for your comment.
Regards, Rickard
Great article, any news on part 3?
Thanks for your efforts.
Carl
http://OxfordSBSGuy.com
Thanks Rickard for this article – well written, direct and to the point, excellently presented. I appreciate you taking the time to share this with the VMware community, and I too look forward to the next entry in the series.
Thanks a lot Carl and Seth,
the part III is in progress, I am working on how to study the CPU usage in a fair way. What is tricky is both the exclude the CPU impact from the network bandwith sending tool and also to take in amount that the vmxnet3 driver will likely have a higher CPU usage due to the much larger amount of network traffic passing through the VM, so it need to be compared in a way like MB/s vs CPU cycles.
Very helpful. Thanks for your efforts!
Thank you very much. That was useful.
Many thanks it has helped me sort out a few issues I have been having
Hi All
Could you possibly give me any indication of why in my environment I am not getting nearly the same readings as you are.
I am in the process of trying the above on 2 like for like 2008 R2 guests on the same host ( Dell Poweredge R720, 16 CPU, 8 NIC’s 256GB memory) in a Vsphere 5.1 environment. I am only getting 900 Mbits/sec max but normally around 770Mbits/sec. Have upgraded both machines to VMX-09, tools are current on the same network, same VLAN etc.
Hello Carl,
the speed of around 900 Mbit/s is quite near the practical limit of physical 1 Gbit connections and one possible reason is that the communication is not really vSwitch local. Some perhaps obvious questions, but still: you are certain that the two VMs are actually running on the same host and on the same vSwitch with the same VLANs?
If you have a DRS cluster it is not uncommon for the VMs to be separated for consuming much CPU, which might cause confusion even if the VMs start out on the same host.
Are you also using the same tool (iperf) and parameters? If using something else, like copying large files between VMs, there might be other factors causing the lower than excepted bandwidth throughput.
Regards, Rickard
Hi Rickard
Yes for practical limits you are correct however I see you were getting way over this.
Have double checked that the 2 vm’s were on the same vSwitch (which has for NIC’s shared with a bunch of other vm’s) and while it is in a DRS cluster, at the time of running the exact iperf tests you did above (same parameters) they were on the same host.
So I guess our network is not great, but anything you know of that I could check quickly?
Thanks Carl
Hello Carl,
the physical limits of gigabit networking “should” be very possible to exceed for intra-vSwitch traffic inside the ESXi host. The reason for the questions was if it was possible that the VMs did in fact communicate through the physical network in any way.
However, if you are in fact sure that they are local and you use the same parameters for both “server” and “client” in iPerf, then you should be able to get more than around 900 Mbit/s. How is the CPU usage on your host? And for the VMs used in the test?
A large amount of network traffic could consume many CPU cycles. If the VMs are near 100 % you could try to increase the vCPU count for them.
Regards, Rickard
Hi Rickard
CPU usage is not even near maxing out, the guest server and clients are only hitting 50 odd percent too when IPerf is running.
I found another forum where a guy suggested trying to run both IPerf client and server on the same vm, i.e. using loopback address. So I went ahead and did so and are still getting only 700 odd Mbits/sec. I then enabled Jumbo frames from within Device manager on this vm and that too made no difference!
I am thinking that the actual virtual switch may only be 1GB but are unsure how to check this in VMware as of yet. Thoughts?
HI,
In my environment with vcenter 5.5,when I use E1000 and test the network throughput through iperf,its 3.5gbps but with VMXNET3 its only 1.5gbps,can someone advice,its a windows VM I tested into
Hi Rickard,
Do You think vmxnet3 can help or is the right one for RTP streams?
On Esx5.1 and 5.5 , Sending from a Windows 2008r2 or 2012R2 guest a rtp stream (g711a fax passthrough) , I have a 6ms mean jitter only in outbound (the frame is set to 20ms, but I see a sequence like 15ms,15ms,31ms,15,15,30 etc.etc).
On a windows 2012 on a physical server there’s no issue. I see 1ms of mean jitter at maximum)
On esx I tried a virtual switch with a dedicated Intel (I tried also with Broadcom Net Extreme), I tried with a passthrough device (Nic Intel directpath I/O), I tried a distributed switch,
I tried also follow the “best practice for latency and Voip” Vmware technote, but with no results (disabling lro, interrupt coalesing ..etc.etc).
I have always a mean jitter of 6ms with no other nic traffic and High CPU and memory reservation.
All the test are from a guest on vmware to a notebook connected to a single switch.
What do you think about it?
Thank you so much
kind regards
Max
Hello Max,
and thanks for your comment.
Out-of-the-box the VMXNET3 is best for larger transmits to keep the CPU usage down, by the coalescing of interrupts, which could lead to higher latency for a single small frame. You did not get any difference by disabling this feature?
Have you tried with the emulated E1000E and noticed any difference in the jitter performance?
Regards, Rickard
Hello Rickard,
yes , vmxnet3 increase performance, but I think my issue is related to a something else.
I tried with E1000E and a Nic in passthrough, but the issue happens also without any other network traffic.
I think it’s not related to Vmware.
If I install a “sql server 2008 R2” (not an express, not a 2012 sql server) I can send the rtp streaming with a stable framing and a Jitter < 0,05 ms. If I stopped Sql server 2008, the Mean Jitter goes to 6ms.
I don't know, maybe is something inside the Windows guest that only Sql Server 2008 uses in the right way.
I discovered it yesterday… I don't know where and what looking for 🙂
Thanks your answer 🙂
Max
Thank you very much Rickard!
Hey Rickard,
During upgrades of the nics to vmxnet3 (on vsphere 6) we have experienced performance isssues between guest OS when they are located at different vmwarehosts.
However it works great while the guest OSes are located on the same vmwarehost or while RSC/LRO is disabled.
Have you experienced this in your work?
Hello Philip,
and thank you for your comment.
I have not seen this myself, but might be able to do some tests later in an ESXi 6.0 environment to see if I could reproduce it.
What kind of performance issues do you see while communicate inter host?
Best regards,
Rickard
Thanks for your fast answer.
We have mainly had issues between for example webservers and databases on windows server 2012 r2 as the RSC was introduced in windows server 2012.
Websites can take 20 seconds to load while they only take a second when the featurer is disabled. Due to NIC-manufactor our NICs support the RSC/LRO feature. I will try to change from cisco-switch to other brand to exclude it being a switch problem.
Hey Rickard and Philip, we are seeing the same issue as you are Philip. If we have the servers on the same hosts, they work fine. When they talk on different hosts with vmxnet3, it is slow. Did you ever find a resolution?
Hey Shane,
by disable Receive Segment Coalescing (RSC) on ur NIC in windows envirement, most of the issue seems to be “solved”.
Hey Shane – after disabling the RSC, did that solve your issue? I have a similar problem with workstations connecting to the Virtual Server, and having a slow response nearly every 20 mins, whilst a Virtual Workstation on the same VSwitch is flawless..
Hey Philip/Richard, have you seen this from VMWare..
https://kb.vmware.com/selfservice/microsites/search.do?language=en_US&cmd=displayKC&externalId=2129176
Hi Rickard, you are really Nobel 😉 🙂 😀
First of all thanks a lot for this great piece of information, really informative & essential. We need champs like you.
In fact, i met with a friend who was having issues related to E1000 with Win 2012 R2 on vCloud Director 5.5 last week on my visit to France.
His server was becoming out of network automatically, No PING, no RDP etc.
I suggested him your articles for more deep understanding on the topic. He studied, he resolved the issue by himself & now is very grateful to you 😉 🙂
May the Force always be with you.
thank you for explanation – appreciated
Just wanted to add a few pieces of information to this article:
Most 1GbE or 10GbE NICs support a feature called interrupt moderation or interrupt throttling, which coalesces interrupts from the NIC to the host so that the host doesn’t get overwhelmed and spend all its CPU cycles processing interrupts.
However, for latency-sensitive workloads, the time the NIC is delaying the delivery of an interrupt for a received packet or a packet that has successfully been sent on the wire is the time that increases the latency of the workload.
Note that while disabling interrupt moderation on physical NICs is extremely helpful in reducing latency for latency-sensitive VMs, it can lead to some performance penalties for other VMs on the ESXi host, as well as higher CPU utilization to handle the higher rate of interrupts from the physical NIC.
Disabling physical NIC interrupt moderation can also defeat the benefits of Large Receive Offloads (LRO), since some physical NICs (like Intel 10GbE NICs) that support LRO in hardware automatically disable it when interrupt moderation is disabled, and ESXi’s implementation of software LRO has fewer packets to coalesce into larger packets on every interrupt. LRO is an important offload for driving high throughput for large-message transfers at reduced CPU cost, so this trade-off should be considered carefully.
VMware recommend you choose VMXNET 3 virtual NICs for your latency-sensitive or otherwise performance-critical VMs. VMXNET 3 is the latest generation of our paravirtualized NICs designed from the ground up for performance, and is not related to VMXNET or VMXNET 2 in any way. It offers several advanced features including multi-queue support: Receive Side Scaling, IPv4/IPv6 offloads, and MSI/MSI-X interrupt delivery.
VMXNET 3 by default also supports an adaptive interrupt coalescing algorithm, for the same reasons that physical NICs implement interrupt moderation. This virtual interrupt coalescing helps drive high throughputs to VMs with multiple vCPUs with parallelized workloads (for example, multiple threads), while at the same time striving to minimize the latency of virtual interrupt delivery.
However, if your workload is extremely sensitive to latency, then we recommend you disable virtual interrupt coalescing for VMXNET 3 virtual NICs.
Another feature of VMXNET 3 that helps deliver high throughput with lower CPU utilization is Large Receive Offload (LRO), which aggregates multiple received TCP segments into a larger TCP segment before delivering it up to the guest TCP stack. However, for latency-sensitive applications that rely on TCP, the time spent aggregating smaller TCP segments into a larger one adds latency. It can also affect TCP algorithms like delayed ACK, which now cause the TCP stack to delay an ACK until the two larger TCP segments are received, also adding to end-to-end latency of the application.
Therefore, you should also consider disabling LRO if your latency-sensitive application relies on TCP.
/Henrik
Hi,
I am using ESXi v6.0, I have created a vSwitch1 without attach to a physical adapter, I also configured to use vmx3, but my network could only reach at 107 Mbps upload 🙁 Should I enable Traffic Shaping?
Any idea will be very appreciated!
My Best,
Hung Tran
Hello Hung,
Traffic Shaping will do nothing for this situation, it will only affect outgoing traffic to the physical network and can only decrease your performance and not the other way around.
Do I understand it as you have two internals VMs on a isolated vSwitch only?
Regards Rickard
Hi,
Thanks for the article.
Just wanted to verify is there any relation between para-virtualized driver (VMXNET3) and
Direct Path I/O settings in VMWare ?
Are both supplementary or complementary or independent
Hello Karanjot, there are no specific relation between these. The Direct Path IO is a way to give the VM direct control over a physical NIC, bypassing the network virtualization layer while the VMXNET3 is a virtual network card visible to the VM but connected to an ordinary vSwitch.
I am still waiting for that part 3
Hi there,
Great article.
Does out of date VMware Tools cause any issues or upset with the VMXNET3 adapter?
Thanks,
Great article!
Thank you!