
The VMware Thick Eager Zeroed Disk vs the Lazy Zeroed Thick disk in write performance.
What is the potential write performance difference between the VMware virtual disks: Thick Lazy Zeroed, Thick Eager Zeroed and Thin provisioned types? This has been discussed for many years and there are many opinions regarding this, both in terms of test vs real life write behavior as well as test methods. There is also important factors as storage effiency, migration times and similar to this, however I will in this article try to make the potential “first write” impact more easy to evaluate.
Before the virtual machine guest operating system can actually use a virtual disk some preparations has to be accomplished by the ESXi host. The main tasks that has to be done for each writable part of a virtual disk is that the space has to be allocated on the datastore and the specific disk sectors on the storage array has to be safely cleared (“zeroed”) from any previous content.
In short, this is done in the following way:
Thin: Allocate and zero on first write
Thick Lazy: Allocate in advance and zero on first write
Thick Eager: Allocate and zero in advance
There are some published performance tests between these three disk types often using the standard tool IOmeter. There is however a potential flaw to these tests, caused by the fact that before IOmeter starts the actual test it will create a file (iobw.tst) and write data to each part of that file – which at the same time causes ESXi to zero out these blocks on the storage array. This means that it is impossible to use IOmeter output data to spot any write performance differences between the three VMware virtual disk types, since the potential difference in write performance will already be nullified when the IOmeter test actually begins.
When the difference will only be in the very first write from the Virtual Machine across the virtual disk sectors a way to simulate this is to force a massive amount of writes over the whole disk area and note the time differences. This is of course not how most applications work in the sense that it is uncommon to do all writes in one continuous stream and instead the “first-writes” with ESXi zeroing is likely to be spread over a longer period of time, but sooner of later each sector that is used by the guest operating system has to be zeroed.
A way to simulate large amounts of writes could be done from using the standard Windows format tool which, despite some popular belief, actually erases the whole disk area if selecting a “full” / non-quick format. In real life there is not much specific interest how fast a partition format is done in itself, however in this test the format tool is used just to create a massive amount of “first-writes”.

This test case uses a VM with Windows 2012 R2 which was given three new virtual hard disks of 40 GB each, where there was one Eager, one Lazy and one Thin. Each disk was then formatted with NTFS, default allocation unit, no compression, but with the non-quick option.
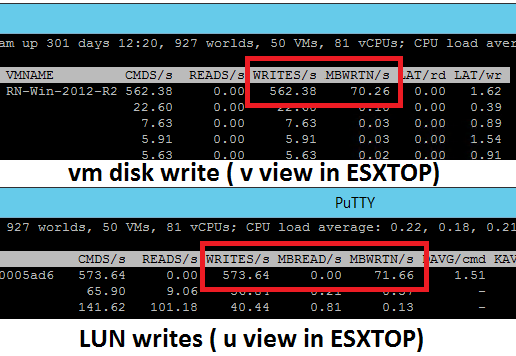
One first observation was in ESXTOP while looking at the ratio between the writes that the virtual machine actually commits compared to how many writes are being sent from ESXi to the LUN.
Above we can see ESXTOP while doing a full format of an Eager Zeroed Thick disk. The important point here is that the numbers are very close. The writes being done at the LUN are only the writes the VM wants to make, i.e. there is no ESXi introduced extra writes since the “zeroing” was done already in advance.

Above a Lazy Zeroed Thick Disk is being full formated from inside the VM.
What could be noticed is the amount of write IOs being sent from ESXi to the LUN is much higher than the number of write IOs coming from the virtual machines. This is the actual zeroing taking place “in real time” and will make the VM write performance lower than the Eager version while accessing new areas of the virtual disk for the first time.
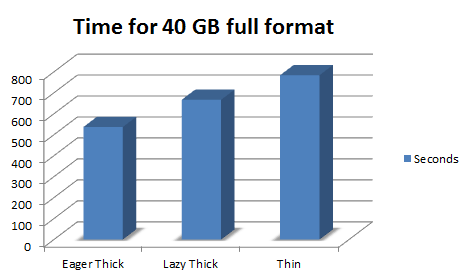
The actual time results for doing a full format of a 40 GB virtual disk was:
Eager Zeroed Thick Disk: 537 seconds
Lazy Zeroed Thick Disk: 667 seconds
Thin Disk: 784 seconds
The Eager Zeroed Thick Disk was almost 25 % faster in first-write performance compared to the Lazy Zeroed.
The Eager Zeroed Thick Disk was almost 45 % faster in first-write performance compared to the Thin Disk.
This is obvious in doing a full format which forces the VM to write at all sectors. In a real environment the “first-writes” will naturally be spread over a longer period of time, but sooner or later the Zeroing hit will take place for each part of the disk and might or might not be noticeable to the user. For a typical virtual machine that does the majority of “first-writes” at OS installation this is likely to be of lesser interest, but for VMs with databases, logfiles or other write intensive applications it is possible to result in a higher impact.

One important thing to notice is also that after the first-write is done the write performance is the same between all three disk types. This could be proven by doing several full formats of the same VMDK disk. On the first format the zeroing will be done (for the Lazy and Thin types), but when the whole disk is zeroed the write performance is identical.
Above a 5 GB VMDK disk was formated three times. The Eager was the fastest on the first format since the zeroing is done before the disk is even visible to the VM and the Lazy and Thin was slower as expected on the initial format run.
However, after the zeroing from ESXi is done the write performance is identical, which is visible above where all three disk performs the same on format run 2 and 3 on the same disk.
The Eager Zeroed Thick Disk will be faster on first write IO on each new part of the disk where Lazy and Thin is slower, however after the disk blocks are zeroed the write performance is the same.
Hi!
Great article!
You don’t mention where the test LUN’s are provisioned from. I guess there are big differences on how zeroing are handled on different modern storage arrays (often pointer based), and also how complete, and how good the different VAAI features are implemented by the different vendors.
Hello,
and thank you for your comment. You make a good point about the importance of the storage array, the system was a HP 3PAR StorServe with the specific LUN backed only by SSD drives. The 3PAR has all the VAAI capabilities which is very good of course, however I am not sure how much they do make a difference in this case.
The VAAI write-same is great for creating the Eager Zeroed Thick type, the 40 GB disk used here took only about 13 seconds to create – likely a combination of the VAAI write-same together with the 3PAR zero-detect function. This makes it very quick to create the VMDK itself but does not really change the VM access after the VMDK is presented to the VM which was studied here.
The 3PAR has hardware detection of “zero writes” to save space, but it was impressive to see that this did not make the access any slower when the “zeroed” block was actually used by the VM.
Another VAAI function that might impact is the ATS, which makes less (or none) SCSI reservation needed when expanding the Thin disk type. My guess is that the ATS capability did help the Thin being faster in the test (and in production also less impact on other VMs on the same LUN), but the thin type was still the slowest of the three.
Best regards, Rickard
can we know where the log was locate for activity on changes from eg: from lazy to eager zero.
I’m try to find from esxi vmkernel and also *.log, at the moment did not find.
Hello,
I have not been looking specifically for the log entries together with disk type changes, so I have no answer for you unfortunately.
Regards, Rickard
Found this article from a link in the Veeam Forums Digest. Just to be a little contrary, we need to acknowledge that the minor improvement of Thick-Eager at the beginning of a vmdk life cycle is only important for very specific high performance machines. Do not let anyone think this means they should never use Thin! If all our non-critical machines were Thick we could never afford all the storage to provision them after making the volumes large enough for the OS and Applications to see “recommended” free space. Such as customers who insist they must have a 2TB data volume, even though three years later they have still only used 450GB :{
I still prefer to let the SAN handle the over-provisioning so would only use thin-provisioning on a VM for DAS storage personally, I’d certainly avoid combining both.
A good article here though and probably as good a test as is feasible without setting up 3 identical system with apps/DBs and complex test scripts simulating user activity. Personally I always provision thick/lazy, mostly as I’m not convinced it makes much real-world difference (and this article doesn’t change my mind on that) and I generally can’t be bothered waiting for multi-TB VMDK creation using thick/eager
Hi and then there always pops up the pRDM vs vmdks discussion next to this one.
There is a very old VMware paper on this which we can use as worst case scenarion in such discussions. (VMware made improvements over the last 8 years…
https://www.vmware.com/techpapers/2008/performance-characterization-of-vmfs-and-rdm-using-1040.html
Very important article to understand the performance differences between them, thank you!
Thin Provisioning is very good for the vast majority of virtual workloads. Bear in mind that the workload of provisioning and zeroing disk is spread over the whole ESX host and the storage array, and is done asynchronously before the VM fills up the space already allocated to it, so it is rare for the workload to overstress the VM.
Bear in mind also that it is far easier to move thin virtual disks around, for example if you want to rearrange your LUNs and datastores. If you thick provision everything you can find yourself gridlocked with nowhere to go.
I tell my sysadmins they should use Thin for just about everything, but if they really need high performance disk IO to use Thick Eager.
I can’t see any use case for Thick Lazy at all, I don’t even know why that option is included, and when I find sysadmins have used it I want to jam their noses into it like a dog that’s forgotten its house training. Can anyone see any point in having Thick Provision Lazy Zero?
The case for Lazy Zeroed Thick Disk is in my opinion that you lower the risk of full datastores (can still happen with running snapshots), but that every day risk is higher with Thin Disk.
Yes, fair point, as a way of leaving some snapshot space. I’m lucky enough to have backup from SAN snapshots, so my VM snapshots last only a few seconds and I don’t give them much thought.
It’s the default setting when provisioning a vmdk and there is no way to change it as default I asked VMware if it could be and the answer was no.
In case of Thick Eager provisioning, if data is deleted from the partition then will it make all the blocks zeroed.?
Will it be as fast as it was in the first write.?
Hello Rahul,
thank you for your comment. I do however not really understand your question.
Anything deleted from the logical file system will already been written to in the first place, so the sectors will be “zeroed” and both the delete and a potential replace will be fast.
thanks for all. good shares !
Great article, thanks!
The ESXi 6.5 Web Host Client only offers two choices for provisioning, when deploying an OVA: “Thin” or “Thick.”
I’ve been searching numerous forums in hopes of determining whether “Thick” means “Eager Zeroed” or “Lazy Zeroed” in ESXi 6.5, but I can find no explanation. In fact, even the VMWare ESXi 6.5 Administrator’s Guide still documents the availability of all three choices, but that’s not what I’m seeing when I deploy an OVA with the 6.5 HTML-based client.
Repeating myself, I can only choose “Thin” or “Thick.” I hope that “Thick” means “Thick Eager Zeroed” in ESXi 6.5. Do you know if that’s the case?
Thank you!
Hello Mike,
and thanks for your comment.
I have not really looked at the vCenter deployed disk type, but if I would be forced to guess I would think that “thick” would mean Lazy Thick in that context.
If you are worried about that and have the license for Storage vMotion there is always the possibility to move the VM to some other datastore and change disk type while doing the transfer (and then move it back if needed).
Good idea. Thanks Rickard!
Following up from a few months ago…
I have been concerned about how the ESXi 6.7 embedded host client will not allow you to deploy an OVA as Eager-Zeroed Thick Provisioned VM, even though it does allow to create a new VM, selecting Eager-Zeroed Thick Provisioned. We were able to select all three types for both Create VM and Deploy OVA, in the now obsolete .NET-based 6.0 vSphere client.
I learned some interesting things researching this problem today and doing some testing:
1) If creating a new VM with ESXi 6.7 vSphere client, it will present all three choices: Thin Provisioned, Lazily-Zeroed Thick Provisioned or Eagerly-Zeroed Thick Provisioned.
2) If deploying an OVA or OVF with the html-based ESXi 6.7 vSphere client, it will allow you to choose only Thin or Thick – and it does not say which version of Thick it will create!
3) As we discovered with ECX 3.3 and ESXi 6.5 on the FT server, Eager-Zeroed Thick is the preferred format, but…
Going back to item 2, above, it turns out that if you select “Thick” when deploying an OVA, you end up with Lazily-Zeroed Thick, not Eagerly-Zeroed thick, so…
All of your “first writes” will be 25% slower than they could be if the entire VMDK had been zeroed in advance, at the time of deployment. It seems crazy that VMWare limits OVA and OVF deployments to only Thin or Thick and has chosen to use Lazily-Zeroed Thick instead of Eagerly-Zeroed, but that’s what you get with ESXi 6.7. Uggh!
4) This can be seen by editing the VM’s settings and looking at the Hard Disk Type – It will show “Thick provisioned, lazily-zeroed” after selecting “Thick” during deployment.
5) This can further be proven by issuing the following command via Putty:
vmkfstools -D 0, the .VMDK has not yet been fully zeroed and, thus, was either created as a new VM or deployed from OVA with the Lazily-Zeroed Thick format.
7) To convert a Lazily-Zeroed, Thick format VMDK to Eagerly-Zeroed (i.e. to zero out the remaining pre-allocated blocks of the “Thick” deployment), you can run the following command via Putty:
vmkfstools -k <— This requires that the VM be Powered Off! Note that it specifies the .vmdk, not the -flat.vmdk file.
This command will take a few minutes to complete, providing a progress counter that goes up to 100%.
8) Running the following command again, will show that there are no blocks remaining to be zeroed. ( i.e. tbz = 0 )
vmkfstools -D
9) But if you then go back into the VM’s Settings and look at Hard Disk Type – surprise – it will still display a type of Lazily Zeroed, Thick Provisioned! That’s got to be a bug in 6.7.
10) I performed eight 10GB text file copies as “first write” tests with the UCE VM, both before and after conversion from a deployed Lazily-Zeroed Thick format to Eagerly-Zeroed Thick, averaging a 23.8% improvement in “first write” speed – which correlates very well with the 25% improvement reported by Rikard and is quite similar to what happens when a bunch of Windows Cumulative Updates have finished downloading within a VM and start unpacking, immediately prior to installation – putting a heavy “first write” load on that VM.
11) It gets more interesting still (or perhaps more boring): If you deploy an OVA, selecting Thin, instead of Thick, you will, of course, end up with a Thin Provisioned VMDK, but it’s much easier to convert it into an Eagerly-Zeroed Thick Provisioned VM, when using the ESXi 6.7 vSphere client, just by Powering Off, then browsing to the VM’s folder in the appropriate datastore, right-clicking on the .vmdk file and selecting “Inflate disk.” It will pre-allocate and zero the remainder of the VM’s total allocation, delivering an Eagerly-Zeroed Thick VM, without having to use Putty to issue commands via SSH. This procedure takes a lot longer than when using the vmkfstools -k command to zero un-zeroed blocks in a Lazily-Zeroed Thick .vmdk, but you will have saved time when first deploying the OVA as a Thin VM.
Optional: Before Inflating the Thin VM, issuing the vmkfstools -D command against the VM’s -flat.vmdk file, will display tbz = 0, because it zeroes sectors immediately following any new allocation of space.
After Inflating the Thin VM, issuing the vmkfstools -D command against the VM’s -flat.vmdk file, will again display tbz = 0, but now, the value for nb (number of blocks) will be much larger, having expanded fully from the original Thin Provisioned allocation.
ALL THAT TO CONCLUDE WITH THIS ADVICE FOR 6.7 USERS:
When DEPLOYING an OVA or OVF with ESXi 6.7’s html-based vSphere client, ALWAYS select “Thin” instead of “Thick” with the checkmark removed for Power On after deployment. Then, with it still powered off, browse to the datastore, right-click the VM’s .vmdk, and select “Inflate disk.” Tada! You will end up with an Eager-Zeroed Thick Provisioned VM instead of the 25% slower (for first writes) Lazily-Zeroed Thick Provisioned VM, and you will not have had to issue SSH commands to convert it. Better still, it will actually be reported in the VM’s Settings as an Eagerly Zeroed Thick Provisioned disk, unlike what happens with the vmfkstools –k method for converting from a “Thick” deployment.
I was aware of “Inflate disk” (acting against Thin disks) from previous experience, but it was only after trying so hard to find a way to convert a “Thick” OVA deployment, which ends up being Lazily-Zeroed, into Eagerly-Zeroed, for that 25% first-write performance advantage, that it occurred to me to see what version of “Thick” you will get, when you “Inflate disk” after first deploying the OVA as a “Thin” disk. That’s a much easier way to end up with Eager-Zeroed Thick Provisioning – deploy with Thin, then Inflate disk.
Mike
It is definitely very informative and thanks.
Mike, great to see there is a way to make the swap to eager zeroed, even for OVA deployments.
As far as performance improvements, let me add this anecdotal discovery. I was having really slow restore time with my Veeam backup software until I switched to restoring the backed-up files from thick lazy to thick eagered – an option with Veeam restores. I saw a 300% (yes, really!) improvement in restore speed copying data from a physical Veeam server to a Pure storage array. Disk creation time seemed to take a bit longer (maybe 20 seconds), but the restore speed went from 160MB/s to 483MB/s on a 1TB vmdk. Huge win. Since then I’ve been poking around to figure out the downside of just making all my VMs thick eager, and came across this post and figured I’d share my experience.
And to add to the various ways to switch from thin or thick lazy to thick eager, clearly a Veeam restore is another way to do that!
Very important article to understand the performance differences between them!
One good things is to also compare 4K format versus 64K format were obviously i’ve spotted a 300% performance improvment in Writes.
thanks for this articles that also confirm that thick is far better as usual and for many reasons!